C++ 웹서버 개발기
C++을 이용한 웹서버 개발
프로젝트 소개
안녕하세요
이 프로젝트는 웹 클라이언트의 http 요청을 받아서 처리할 수 있는 기본적인 서버를 C++로 만드는 것이 목적입니다.
그래서 저희는 GET, POST, DELETE와 같은 요청을 처리할 수 있으며 파일 업로드같은 요청은 CGI를 통해 처리하는 서버를 구현하였습니다.
또한 NGINX의 config를 참고하여 저희 웹서버 또한 config 파일을 통해 포트, 허용 메소드, url 설정 등을 할 수 있도록 하였습니다.
프로젝트 구현 영상
파트별 구현부
파트 요약
저희 웹서버 프로젝트는 크게 아래의 네 파트로 나눌 수 있습니다.
1. Config 파일을 통한 서버 세팅
저희는 config 파일을 통해서 저희 웹서버의 동작 방식을 정할 수 있도록 하고 싶었습니다. NGINX 웹서버를 써보신 분은 아시겠지만 etc/nginx/nginx.conf 파일을 수정함으로써 어떤 포트를 열어둘 것인지, 어떤 url을 받고, 어떤 메소드를 허용할 것인지 등을 설정할 수 있습니다. 그래서 저희도 NGINX와 비슷한 저희만의 config 파일과 문법을 정립하고 그것을 통해 서버의 동작을 설정할 수 있도록 하였습니다.다음은 저희가 구성한 config 파일의 예시입니다. 프로그램의 실행 인자로 ./webserv conf 이렇게 넘기게 되면 첫번째 파일명이 인자로 들어갑니다. 아래에서 보시듯 conf 파일은 짧지만 include기능을 구현하여 어떤 서버를 만들 것인지에 대한 정보들을 포함할 수 있기에 아래의 내용들이 전부 저희 웹서버의 설정으로 들어가게 되는 것입니다.
# conf
events {
worker_connections 1024;
}
http {
include mime.types;
default_type application/octet-stream;
keepalive_timeout 65;
client_body_timeout 180;
include sites-enabled/server1;
}
# sites-enabled/server1; included in conf file
server
{
listen 8888;
server_name localhost;
client_body_timeout 10;
include server.conf;
}
#server.conf file; included in sites-enabed/server1
location ^ / {
root html;
index index.html index.htm;
}
location ^ /tahm {
allow_methods GET POST DELETE;
root html;
index index.html index.htm;
}
location ^ /auto {
allow_methods GET;
root html;
autoindex on;
}
location ^ /upload {
allow_methods GET POST;
root html;
index file.html;
}
location $ .py {
allow_methods GET POST;
cgi_path /usr/bin/python3;
}
location ^ /google {
proxy_pass http://www.google.com;
}
error_page 500 502 503 504 505 /50x.html;
location = /50x.html {
root html;
}
2. I/O multiplexing으로 다중 클라이언트 처리하기
2.1 기본 상황
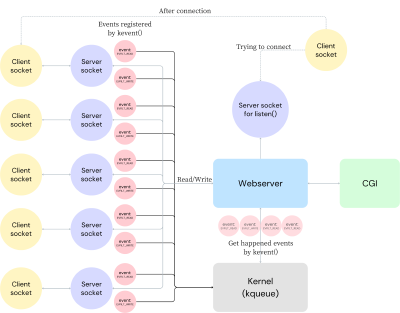
웹서버는 많은 수의 클라이언트로부터 동시에 요청을 받을 수 있고 이것들을 전부 막힘없이 처리해야 합니다. 이것을 하기 위해선 I/O multiplexing이라는 특별한 기술이 필요한데 왜 기본적인 I/O로 처리가 불가능한지와 이 것이 무엇인가에 대해서 설명드리겠습니다.
먼저 하나의 클라이언트만 있을 때의 상황을 생각해보겠습니다. 서버는 클라이언트와 소켓으로 연결됩니다. 서버 소켓이 listen() 함수를 통해 특정 포트를 듣고 있으면 그쪽으로 클라이언트가 연결 요청을 보냅니다. 그러면 현재는 TCP/IP 프로토콜을 이용할 것이므로 3-way-handshake를 거치고 난뒤 새로운 소켓이 만들어져 클라이언트와 연결을 유지하게 됩니다.
이러한 단일 클라이언트 상황에서는 걱정할 점이 많지 않습니다. 단순히 Blocking I/O를 사용할 경우 클라이언트로부터 요청이 올 때까지 기다렸다가 읽거나, Non-Blocking I/O를 사용해서 요청을 기다리지 않으며 다른 일을 할 수도 있는 것이죠. 그러나 다중 클라이언트 상황에서는 상황이 변하게 됩니다.
예를 들어 100개의 클라이언트와 서버가 연결되어있을 때 요청이 들어왔는지 확인하려고 소켓들을 확인하는 상황을 생각해보겠습니다. Blocking I/O를 사용하게 되면 중간에 한번이라도 블락되면 뒤의 요청들은 계속 대기하게 될 것입니다. Non-Blocking I/O를 사용한다 하더라도 계속해서 클라이언트로부터 요청이 왔는지 확인해야하고 최소 100번의 시스템 콜을 사용해야해서 부하가 큽니다.
2.2 I/O multiplexing이란
실제로 이것은 C10K problem이라고도 알려져있는데 10000개의 클라이언트가 연결되었을 때 동시 처리를 어떻게 해야하는가라는 문제가 있었습니다. 그래서 나오게 된 것이 I/O multiplexing이라는 기술입니다. I/O multiplexing이란 단 한번의 시스템 콜을 이용하여 동시에 여러 파일 디스크럽터(이하 fd)들을 모니터링하는 기술입니다. 어떤 시스템 콜이 사용되고, 어떻게 이것이 가능한지는 이후 설명드리겠습니다.
방금 전의 100개의 클라이언트가 있는 상황에 대입해서 생각해보면 I/O multiplexing이란 단 한번의 시스템 콜을 통해서 모든 read() 가능한 클라이언트들을 알아내는 것입니다. 이러한 목적을 달성하기 위해 커널은 클라이언트와 관련된 fd들을 모두 감시하고 있습니다. 그러다가 서버의 요청(시스템 콜)이 오게 되면 event(추후 서술)가 일어난 fd들을 모두 서버에게 알려줍니다. 그래서 서버는 한번의 시스템 콜을 이용하지만 보낸 요청이 있거나 응답을 받을 준비가된 모든 클라이언트들을 바로 알 수 있는 등 100개의 클라이언트와 동시 소통이 가능한 것입니다.
2.3 kqueue 알아보기
I/O multipelxing을 구현하는 select, poll, epoll, kqueue와 같은 다양한 함수가 있지만 저희는 macOS에서 개발을 진행했기때문에 kqueue를 사용하였습니다. 이제 이 함수가 무엇이고 어떻게 작동되는 지 알아봄으로써 왜 한 번의 시스템 콜만으로도 내가 관심을 갖는 fd와 관련된 모든 I/O를 처리할 수 있는지 알아보겠습니다.
알아볼 함수는 kqueue()와 kevent() 총 두개인데 kqueue()에 대해 먼저 알아보겠습니다.
#include <sys/event.h>
int kqueue(void);
이 함수는 새로운 kernel event queue(이하 kq)를 생성하고 그에 대한 fd를 리턴해줍니다. 여기서 event란 특정 fd와 관련하여 어떤 상태나 행동이 발생하는 것으로 이해할 수 있습니다. 구체적인 예는 FreeBSD manual page의 EVFILT(Event Filter) 항목을 참고해보시면 알 수 있습니다.
EVFILT_READ There is data available to read
EVFILT_WRITE Possible to write to the fd
...
저희는 kq에 모니터링하고싶은 event들을 등록할 수 있고 발생한 event들을 리턴받을 수 있습니다. 두 작업은 모두 kevent()를 통해서 이루어집니다.
#include <sys/event.h>
int kevent(int kq, const struct kevent *changelist, int nchanges, struct kevent *eventlist, int nevents, const struct timespec *timeout);
kq에 event를 등록하는 방법은 다음과 같습니다. 우선 EV_SET()를 통해서 몇번 fd의 어떤 상황에 관한 event인지 세팅을 해줍니다. 그 후 kevent()를 통해 그 event를 등록해주게 됩니다.
예시의 경우 특정 클라이언트와 연결된 소켓 fd에 read() 할 것이 있는가와 관련된 event를 만든뒤 kevent() 함수를 통해 event를 등록하는 것입니다.
struct kevent event;
EV_SET(&event, socketFd, EVFILT_READ, EV_ADD, 0, 0, NULL); // event 세팅
kevent(kq, &event, 1, NULL, 0, NULL); // event 등록
Event는 클라이언트로부터 읽을게 있거나, 클라이언트에 응답을 보낼 수 있는 상태가 되었을 때 발생하게 됩니다. 그러면 저희는 아래와 같이 발생한 event들을 받아올 수 있습니다.
아래 예시에서 event_list는 발생한 event가 저장될 배열이고, MAX_EVENTS는 한번에 받아올 event의 개수입니다.
struct kevent eventList[MAX_EVENTS];
int events = kevent(kq, NULL, 0, eventList, MAX_EVENTS, &timeout);
2.4 events들 이용하기
앞서 2.3에서 kqueue()를 통해 kernel event queue를 생성한 후, kevent()를 통해 그 kq에 모니터링하고 싶은 fd들을 등록하였습니다. 그 후 kevent()를 통해 발생한 event들의 목록을 받아올 수 있습니다. 그렇다면 이것들을 어떻게 활용하면 많은 수의 클라이언트들을 관리할 수 있을까요?
우선 이 event라는 것이 어떤 구조체인지 알면 저희의 코드를 이해하는 데 도움이 될 것입니다. 아래의 구조체에서 유의해서 볼 부분은 ident와 filter입니다. FreeBSD manual page에 따르면 ident는 event에 대한 identifier지만 보통은 fd입니다. 또 filter는 위의 EV_SET()을 통해 등록한 그 event filter입니다. 그러므로 저희는 어떤 event가 발생했을 때 ident 값을 통해서 어떤 fd와 관련하여 발생한 event인지, filter 값을 통해서 어떤 종류의 event인지 알 수 있는 것입니다.
struct kevent
{
uintptr_t ident; /* identifier for this event */
short filter; /* filter for event */
u_short flags; /* action flags for kqueue */
u_int fflags; /* filter flag value */
int64_t data; /* filter data value */
void *udata; /* opaque user data identifier */
uint64_t ext[4]; /* extensions */
};
그렇다면 이 지식들을 바탕으로 저희의 웹서브가 동작하는 것을 살펴보도록 하겠습니다. 서버 세팅을 마무리한 뒤 웹서버는 while (1)이라는 무한 루프 안에서 계속해서 kevent()를 호출하여 발생한 event들을 받아오게 됩니다. 그리고 for문을 통해 그 event들을 순회하며 filter == EVFILT_READ라면 그 event와 관련된 fd에는 read()가 가능한 상태이므로 http request를 읽는 시도를 해보는 식으로 작동합니다.
void Webserv::runWebserv()
{
struct kevent eventList[MAX_EVENTS];
struct timespec timeout;
bzero(&timeout, sizeof(struct timespec));
while (1)
{
int events = kevent(kq, NULL, 0, eventList, MAX_EVENTS, &timeout);
if (events == -1)
{
std::cerr << "kevent() error" << std::endl;
continue;
}
for (int i = 0; i < events; i++)
{
int eventFd = eventList[i].ident;
if (isServSock(eventFd))
connectClient(eventFd);
else if (isClientSock(eventFd))
{
if (eventList[i].flags & EV_EOF)
disconnectClient(eventFd);
else if (eventList[i].filter == EVFILT_READ)
{
Connection &conn = findConnectionByFd(eventFd);
if (conn.getRequest().getParseStatus() != End)
conn.readRequest(eventFd);
}
else if (eventList[i].filter == EVFILT_WRITE)
{
Connection &conn = findConnectionByFd(eventFd);
if (conn.getResponse().getResponseState() == Response::Send)
conn.sendResponse();
if (conn.getResponse().getResponseState() == Response::End)
{
if (conn.getStatusCode() || conn.getConnectionClose())
disconnectClient(eventFd);
else
conn.reset();
}
}
}
}
}
}
3. RFC에 기반한 HTTP 요청과 응답 처리
2번 파트에서 본 것과 같이 저희 웹서버는 어떤 event가 발생했을 때, 그 event의 filter값이 EVFILT_READ라면 readRequest()라는 함수를 통해서 http request를 읽고, EVFILT_WRITE라면 sendResponse()를 통해 http response를 클라이언트한테 보냅니다. 이 때 저희는 어떻게 http 프로토콜에 맞추어 request/response를 처리할 수 있을까 생각해보았고, RFC 9110, RFC 9112 두개의 문서를 통해 프로토콜을 파악할 수 있었습니다. RFC란 국제 인터넷 표준화 기구에서 관리하는 기술 표준으로 HTTP, URL, CGI 등 여러 기술들의 표준을 다루는 문서입니다. 뒤에 붙은 숫자는 일련번호로 승인된 문서는 유일한 일련번호를 갖게 됩니다.
3.1 HTTP 요청 처리
아시다시피 HTTP 요청은 크게 status line, headers, body의 세 파트로 나뉘게 됩니다. trailer라는 파트도 있지만 요청이 chunked라는 방식으로 올 때 쓰이는 특수한 것으로 우선은 다루지 않겠습니다.
다음은 크롬의 개발자 도구를 이용하여 실제로 크롬이 보낸 http 요청을 본 것입니다. 맨 윗줄이 status line으로 메소드, url, 프로토콜 관련 정보를 담고 있습니다. 그 뒤로는 헤더들이 쭉 나열되는데 이는 RFC 9110를 통해 자세한 내용과 문법을 파악할 수 있습니다. 헤더들은 요청과 관련된 정보들을 담고있는데 예를 들어 body가 있는 POST 요청의 경우 Transfer-Encoding 헤더들을 살펴보고 헤더값에 chunked가 있는지 등을 통해 body가 어떤 형태로 들어오고 있는지 파악할 수도 있고, Content-length를 통해 전체 body 길이를 알 수도 있습니다.

이런 요청을 받아서 처리하기 위해서 저희는 status line, headers, body 각 단계별로 다른 함수를 통해 요청을 읽어왔습니다. 헤더를 파싱하는 함수를 간략하게 보여드리자면 아래의 코드와 같습니다. header 파트를 한 줄씩 인자로 받아서 key, value값을 istringstream으로 읽어옵니다. 이때 key에 space가 있는 경우나, value의 값이 너무 큰 경우 등의 에러가 있으면 해당하는 status code값을 리턴하는 식으로 에러를 처리합니다. RFC 9110를 더 읽어보면 중복되는 헤더가 있을 경우같은 상황을 처리하는 방법이 나와있어 실제 웹서버는 그부분도 처리할 수 있게 구현되어 있습니다.
int Request::parseHeaders(const std::string &fieldLine)
{
std::istringstream iss(fieldLine);
std::string key, value;
std::getline(iss, key, ':');
if (util::string::hasSpace(key))
{
parseStatus = End;
return 400;
}
std::getline(iss >> std::ws, value, '\r');
if (value.length() > HEADER_LIMIT)
{
parseStatus = End;
return 431;
}
key = util::string::toLower(key);
headers.insert(make_pair(key, value));
return 0;
}
이렇게 헤더가 끝나면 헤더와 바디 파트를 구분짓는 빈 줄인 “\r\n"이 나오게 됩니다. 그럼 이를 통해 바디 파트가 시작됐다는 것을 알 수 있고 소켓에 들어오는 입력을 바디 파트를 처리하는 함수에 넘기게 됩니다. 바디 파트는 두 유형으로 나누어 처리하게 됩니다. Content-length가 있는 경우, Chunked라서 Content-lenght가 없는 경우. Chunked라는 것은 보낼 양이 크거나 해서 전체 길이를 알지 못할 때 부분부분 잘라서 보내는 방법을 의미합니다. 그러므로 Content-length가 없습니다.
3.2 HTTP 응답 보내기
HTTP 요청을 다 읽게 되면 웹서버는 그 정보를 바탕으로 어떤 응답을 보낼 지 일련의 프로세스를 거쳐 판단하게 됩니다. 예를 들어 요청 부분에서 정보가 부족했거나 문법에 맞지않는 입력이 들어왔다면 그에 해당하는 에러코드를 담은 응답을 보내게 됩니다.

에러가 없다면 CGI를 이용해서 처리할 요청인지, 서버 자체에서 처리할 요청인지 분리하여 위와같이 그에 맞는 응답을 생성하여 보내게 됩니다.
void Connection::buildResponseFromRequest()
{
if (statusCode)
{
buildErrorResponse(statusCode);
response.setResponseBuffer();
}
else
{
std::string method = request.getMethod();
response.setStatusLine("HTTP/1.1 200 OK");
response.addToHeaders("Server", "Hafserv/1.0.0");
std::string cgiExecutable = getCGIExecutable();
if (cgiExecutable.size())
{
File cgiFile(cgiExecutable);
if (!cgiFile.isExecutable())
{
statusCode = 500;
buildErrorResponse(statusCode);
return;
}
buildCGIResponse(cgiExecutable);
}
else // non CGI
{
if (method == "GET")
buildGetResponse();
else if (method == "POST")
buildPostResponse();
else if (method == "DELETE")
buildDeleteResponse();
}
}
}
4. CGI
저희는 몇 가지 http 요청들을 처리하기 위해서 CGI를 사용했습니다. CGI wikipedia에 의하면 CGI란 웹 서버가 http 요청을 처리하기 위해서 외부 프로그램을 사용하기 위한 인터페이스 명세입니다. 여기서 인터페이스란 두 개의 시스템이나 장비가 만나는 접점이나 경계면인데요. 즉 CGI, common gateway interface란 웹 서버가 외부 프로그램을 통해 http 요청을 처리할 떄 어떤 정보를 넘겨야 하는 지 등 그 경계면에 관한 명세입니다.
CGI를 사용하게되면 정적인 페이지만 구성할 수 있던 웹서버의 경우 동적인 페이지를 생성할 수 있게되고, CGI가 서버의 일을 대신 해주고 결과만 리턴해줄 수 있으므로 부하도 줄어들 수 있습니다.
저희는 대표적으로 동적인 페이지 구성이나 file upload를 처리하기 위해서 CGI 프로그램을 사용했습니다. 예를 들어 다음과 같은 html이 있으면 action="/upload/upload.py"이기때문에 요청된 url을 통해 어떤 외부 스크립트를 통해 이 페이지에서 생성된 요청을 처리해야할 지 파악할 수 있습니다.
<form action="/upload/upload.py" method="post" enctype="multipart/form-data" accept-charset="UTF-8">
Select file to upload:
<input type="file" name="fileToUpload" id="fileToUpload">
<br><br>
<input type="submit" value="Upload File" name="submit">
</form>
저희가 CGI 프로그램을 사용한 방식은 다음과 같습니다. 어떤 http 요청이 CGI로 처리해야하는 요청이라고 파악되면 buildCGIResponse()를 부르게 됩니다. 간략하게 보여드리기 위해 pipe(), fcntl() 등 에러 처리가 필요한 함수들에 대한 예외처리를 삭제했으나 실제 웹서버에서는 크래쉬를 방지하기 위해 필요합니다.
이 함수 내부에선 fork()를 통해 자식 프로세스(이하 CGI 프로세스)를 만든 뒤, 그 프로세스로 하여금 외부 스크립트를 실행하도록 합니다. 원래의 웹서버 프로세스와 CGI 프로세스는 pipe로 연결이 되게 됩니다. 다른 함수에서 웹서버는 pipe를 통해 http 요청의 본문을 CGI 프로세스에 전달해주게 되고, CGI는 그것을 토대로 한 응답을 pipe로 다시 웹서버에 전달해주게 됩니다.
void Connection::buildCGIResponse(const std::string &scriptPath)
{
int outward_fd[2];
int inward_fd[2];
response.setResponseState(Response::BuildingCGI);
pipe(outward_fd);
pipe(inward_fd);
fcntl(outward_fd[0], F_SETFL, O_NONBLOCK, FD_CLOEXEC);
fcntl(outward_fd[1], F_SETFL, O_NONBLOCK, FD_CLOEXEC);
fcntl(inward_fd[0], F_SETFL, O_NONBLOCK, FD_CLOEXEC);
fcntl(inward_fd[1], F_SETFL, O_NONBLOCK, FD_CLOEXEC);
cgiPID = fork();
if (cgiPID == 0)
{
char *argv[] = {(char *)scriptPath.c_str(), (char *)targetResource.c_str(), NULL};
char **envp = makeEnvp();
close(outward_fd[0]);
close(inward_fd[1]);
dup2(outward_fd[1], STDOUT_FILENO);
dup2(inward_fd[0], STDIN_FILENO);
execve(argv[0], argv, envp);
std::exit(1);
}
else
{
close(outward_fd[1]);
close(inward_fd[0]);
response.setResponseState(Response::BuildingCGI);
Webserv::getInstance().addCGIEvent(socket, readPipe, writePipe);
}
}
마무리
이렇게 C++을 이용하여 웹서버를 만드는 과정을 살펴보았습니다. 기존에 웹서버가 어떻게 동작하는지 자세하게 공부해볼 기회가 없었는데 이번에 소켓 네트워크 단에서부터 직접 알아볼 수 있는 좋은 기회가 되었던 것 같습니다. 프로젝트를 마치고 이렇게 블로그에 정리해보니 계속해서 의문이 생기는 부분이 있군요. 밑의 추가 공부 파트에 적어놓았는데 계속해서 다뤄보도록 하겠습니다. 이번 학기에 운영체제와 시스템 프로그래밍을 수강하게되는데 몇몇 부분은 해당 과목에서 다룰 내용과 겹쳐보이기도 합니다. 다음 글에서 뵙겠습니다.
추가 공부
- 소켓을 recv/send가 아닌 read/write로도 접근이 가능한 이유? (Virtual File System)
- system call을 사용할 시 kernel과 user space간 스위칭은 어떻게 일어나는지?
- 라우팅 등을 거쳐 랜선을 통해 들어온 정보가 어떻게 프로세스로 전해지는 것인지, socket establishment되어서 딱 서버랑 클라이언트 1:1 대응이 되는 방식
- kqueue는 왜 kernel queue를 쓰는지? epoll은 kernel red-black tree를 사용하는데 반해서